14 Abschluss
14.1 Lernsteuerung
14.1.1 Lernziele
Nach Absolvieren des jeweiligen Kapitels sollen folgende Lernziele erreicht sein.
Sie können …
- erläutern, wie Sie eine typische, sozialwissenschaftliche Forschungsfrage (quantitativ) untersuchen
- typische “Lieblingsfehler” benennen und Wege aufzeigen, um die Fehler zu umgehen
- zwischen den Grundkonzepten der Frequentististischen Statistik und der Bayes-Statistik übersetzen
- die Grundideen der Bayes-Statistik in eine Gesamtzusammenhang einordnen
14.1.2 Benötigte R-Pakete
In diesem Kapitel benötigen Sie folgende R-Pakete.
14.1.3 Begleitvideos
14.2 Probeklausur
14.2.1 2024
(Diese Liste ist im Aufbau. Bitte konsultieren Sie für weitere Aufgaben selbständig alle relevanten Aufgaben, die in den Kapiteln vorgestellt wurden.)
- ttest-als-regr
- Additionssatz1
- Nerd-gelockert q
- Urne1
- corona-blutgruppe
- voll-normal
- alphafehler-inflation3
- verteilungen-quiz-05
- verteilungen-quiz-03
- verteilungen-quiz-04
- Kekse03
- globus-bin2
- globus2
- iq01a
- gem-wskt4
- Rethink2m3
- mtcars-post2a
- groesse03
- bath42
- klausur-raten
- bed-post-wskt1
- mtcars-post3a
- exp-tab
- norms-sd
- mtcars-post_paper
- bfi10
- rope-luecke
- wskt-schluckspecht2a
- penguins-stan-06
14.2.2 2023
Dieser Tag auf dem Datenwerk stellt Fragen einer Probeprüfung (Version 2023) zusammen.
14.2.3 2022
Dieser Tag auf dem Datenwerk stellt Fragen einer Probeprüfung (Version 2022) zusammen.
14.3 Lieblinglingsfehler
Lieblingsfehler im Überblick 🤷:
- Quantile und Verteilungsfunktion verwechseln
- Prädiktoren nicht zentrieren, wenn es einen Interaktionsterm gibt
- Interaktion falsch interpretieren
- Regressionskoeffizienten kausal interpretieren, wenn es keine kausale Fundierung gibt
14.3.1 Post-Präd-Verteilung (PPV) und Post-Verteilung verwechseln 🤷
🏎 🏎 Vertiefung: Dieser Abschnitt ist nicht prüfungsrelevant. 🏎️ 🏎
Berechnen wir unser Standard-mtcars-Modell: mpg ~ hp.
m1 <- stan_glm(mpg ~ hp, data = mtcars, refresh = 0)Die Post-Verteilung zeigt Stichproben zu den Parameterwerten, s. Tabelle 14.1.
Diese Tabelle kann man hernehmen, um Fragen zu Post-Verteilung zu beantworten. Häufig ist es aber bequemer, z.B. mit parameters(m1) Post-Intervalle und Punktschätzer auszulesen.
Die Posterior-Prädiktiv-Verteilung (PPV) zeigt die Vorhersagen, also keine Parameterwerte, sondern Beobachtungen.
14.3.2 Quantile und Verteilungsfuntion verwechseln 🤷
14.3.2.1 Quantil für \(p\)
Ein \(p\)-Quantil teilt eine Verteilung in zwei Teile, und zwar so, dass mind. \(p\) kleiner oder gleich dem \(p\)-Quantil sind. s. Abbildung 14.1.

Das 50%-Quantil (.5-Quantil) beträgt \(x=0\). Mind ein Anteil \(1-p\) ist größer oder gleich dem \(p\)-Quantil.
14.3.2.2 Verteilungsfunktion \(F\)
\(F(x)\) gibt die Wahrscheinlichkeit an der Stelle \(x\) an, dass \(X\) einen Wert kleiner oder gleich \(x\) annimmt, s. Abbildung 14.2.

\(F(0)=1/2\), die Wahrscheinlichkeit beträgt hier 50%, dass \(x\) nicht größer ist als 0.
14.3.3 Interaktion falsch interpretieren 🤷
Berechnen wir ein einfaches Interaktionsmodell: mpg ~ hp*vs.
Zur Erinnerung: mpg ~ hp*vs ist synonym zu (aber kürzer als) mpg ~ hp + vs + hp:vs.
m2 <- stan_glm(mpg ~ hp*vs, data = mtcars) # mit InteraktionseffektModellkoeffizienten, s. Tabelle 14.2.
parameters(m2)| Parameter | Median | 95% CI | pd | Rhat | ESS | Prior |
|---|---|---|---|---|---|---|
| (Intercept) | 24.58 | (19.07, 29.94) | 100% | 1.001 | 2293 | Normal (20.09 +- 15.07) |
| hp | -0.04 | (-0.07, -0.01) | 99.80% | 1.001 | 2364 | Normal (0.00 +- 0.22) |
| vs | 14.22 | (5.76, 23.58) | 100% | 1.002 | 1549 | Normal (0.00 +- 29.89) |
| hp:vs | -0.11 | (-0.20, -0.03) | 99.85% | 1.001 | 1665 | Normal (0.00 +- 0.31) |
Tabelle 14.2 zeigt die Visualisierung der Parameter von m2.
plot(parameters(m2))
Falsch 😈 Der Unterschied im Verbrauch zwischen den beiden Gruppen vs=0 und vs=1 beträgt ca. -0.11.
Richtig 👼 Der Unterschied im Verbrauch zwischen den beiden Gruppen vs=0 und vs=1 beträgt ca. -0.11 – wenn hp=0.
Da hp=0 kein realistischer Wert ist, ist das Modell schwer zu interpretieren. Zentrierte Prädiktoren wären hier eine sinnvolle Lösung.
14.4 Kochrezepte 🍲
14.4.1 Kochrezept: Forschungsfrage untersuchen
Theoretische Phase 1. Staunen über ein Phänomen, \(y\), Kausalfrage finden 2. Literatur wälzen, um mögliche Ursachen \(x\) von \(y\) zu lernen 3. Forschungsfrage, Hypothese präzisieren 4. Modell präzisieren (DAG(s), Prioris)
Empirische Phase
- Versuch planen
- Daten erheben
Analytische Phase
- Daten aufbereiten
- Modell berechnen anhand eines oder mehrerer DAGs
- Modell prüfen/kritisieren
- Forschungsfrage beantworten
Yeah! Fertig.
14.4.2 Parameter schätzen vs. Hypothesen prüfen
Quantitative Studien haben oft einen von zwei (formalen) Zielen: Hypothesen testen oder Parameter schätzen. Beispiel Hypothesenprüfung: “Frauen parken im Durchschnitt schneller ein als Männer”. Beispiel Parameterschätzung: “Wie groß ist der mittlere Unterschied in der Ausparkzeit zwischen Frauen und Männern?”
Je ausgereifter ein Forschungsfeld, desto kühnere Hypothesen lassen sich formulieren: - stark ausgereift: - Die nächste totale Sonnenfinsternis in Deutschland wird am 27.7.2082 um 14.47h stattfinden, Quelle - gering ausgereift: - Die nächste Sonnenfinsternis wird in den nächsten 100 Jahren stattfinden. - Lernen bringt mehr als Nicht-Lernen für den Klausurerfolg. Kühne Hypothesen sind wünschenswert 🦹
14.4.3 Formalisierung von Forschungsfragen
Der Mittelwert in Gruppe A ist höher als in Gruppe B (der Unterschied, \(d\), im Mittelwert ist größer als Null):
\[\mu_1 > \mu_2 \Leftrightarrow \mu_1 - \mu_2 > 0 \Leftrightarrow \mu_d > 0\]
14.5 Kerngedanken Bayes
14.5.1 Zentraler Kennwert der Bayes-Statistik: Post-Verteilung
Berechnen wir wieder ein einfaches1 Modell: mpg ~ hp.
m3 <- stan_glm(mpg ~ hp, data = mtcars)Und schauen wir uns die Post-Verteilung an, mit eingezeichnetem HDI, s. Abbildung 14.4.
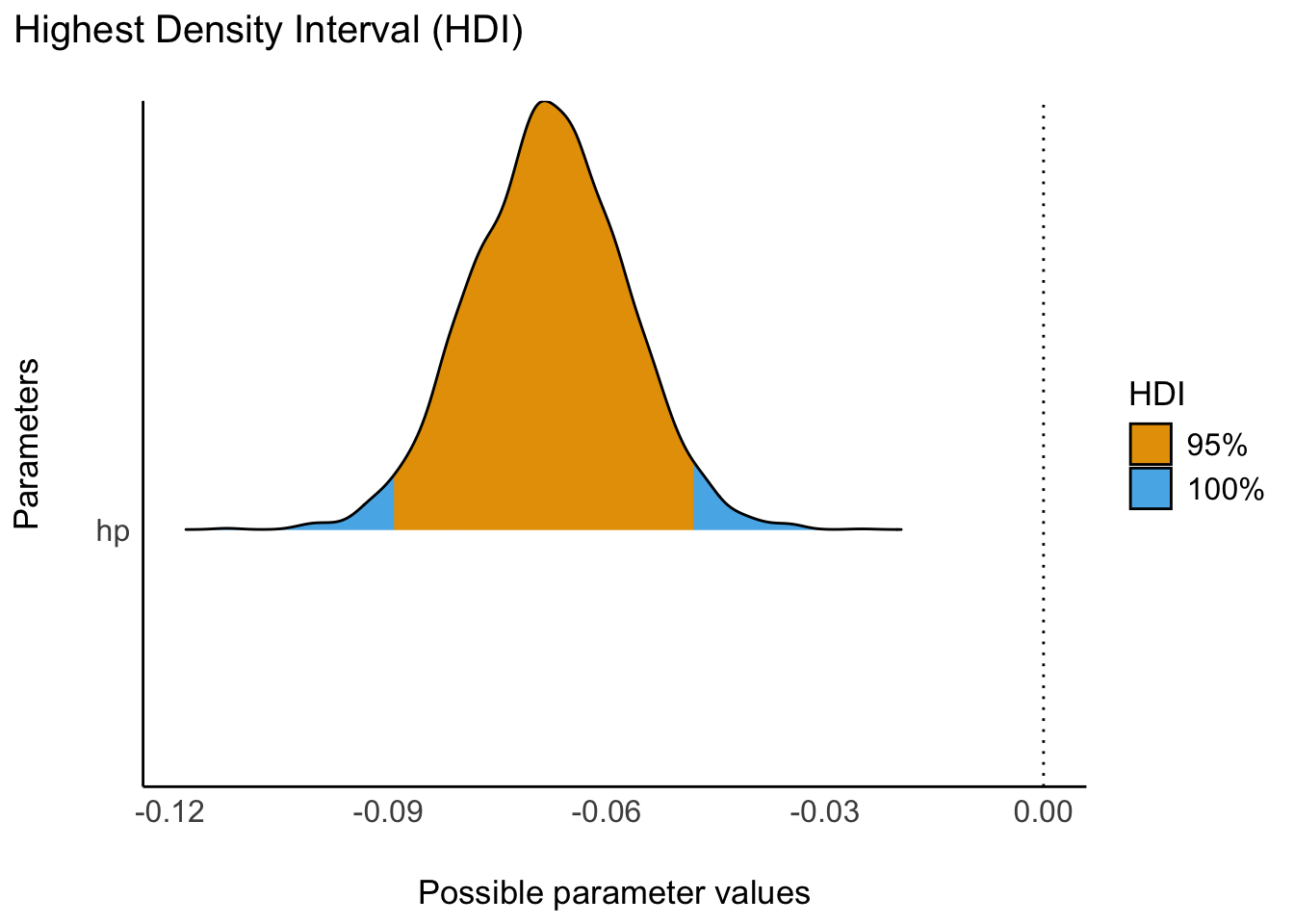
Ein Zusammenfassen der Posterior-Verteilung (z.B. zu einem 95%-PI) ist möglich und oft sinnvoll. Verschiedene Arten des Zusammenfassens der Post-Verteilung sind möglich, z.B. zu Mittelwert oder SD oder einem einem HD-Intervall. Allerdings übermittelt nur die gesamte Post-Verteilung alle Informationen. Daher empfiehlt es sich (oft), die Post-Verteilung zu visualisieren.
14.5.2 Posteriori als Produkt von Priori und Likelihood
\[\text{Posteriori} = \frac{\text{Likelihood} \times \text{Priori}}{\text{Evidenz}}\]
14.6 Beispiele für Prüfungsaufgaben
14.6.1 Geben Sie den korrekten Begriff an!
🌬🚙🙋️👨⬅️Hans 👧⬅️Anna 👩⬅️Lise
Puh, wie erstelle ich für alle Studis ein anderes Rätsel2?
14.6.2 DAG mit doppelter Konfundierung
Puh, jetzt kommt ein wilder DAG, s. Abbildung 14.5.

Definition 14.1 (Minimale Adjustierungsmenge) die Minimale Adjustierungsmenge für x und y gibt eine kleinstmögliche Menge an an Knoten eines DAGs an, die zu adjustieren sind, um den kausalen Effekt von x auf y zu bestimmen (zu “identifizieren”). \(\square\)
❓Geben Sie die minimale Adjustierungsmenge (minimal adjustment set) an, um den totalen (gesamten) Effekt von E auf D zu bestimmen!
❗ Entweder ist die Menge {A,Z} zu adjustieren oder die Menge {B,Z}.
Ja, dem DAG ist zu helfen.
14.6.3 DAG mit vielen Variablen
Je nach dem wie komplex Ihre Theorie ist, ist Ihr DAG auch komplex, s. Abbildung 14.6.
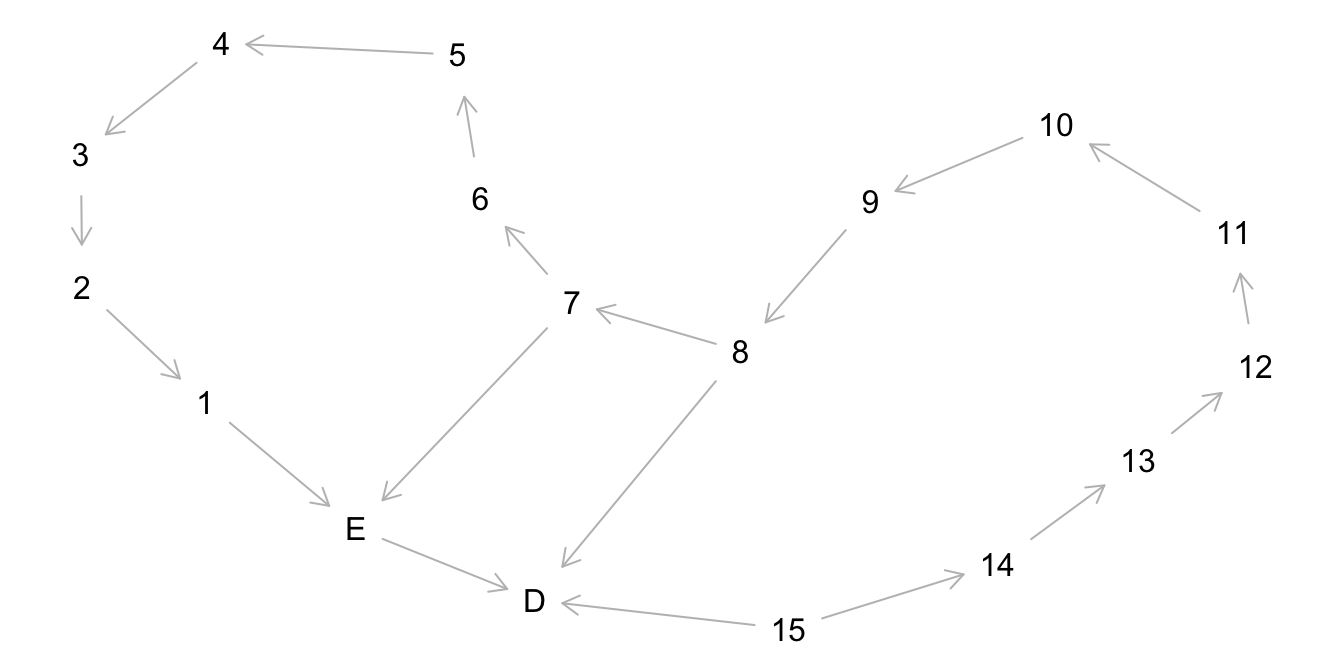
Minimale Adjustierungsmenge, um den Effekt von E auf D zu identifizieren: {7}, {8}.
Trotz der vielen Variablen, ist der kausale Effekt von E auf D recht gut zu identifizieren.
14.6.4 Ein Kausalmodell der Schizophrenie, van Kampen (2014)
The SSQ model of schizophrenic prodromal unfolding revised:
An analysis of its causal chains based on the language of directed graphs
D. van Kampen
Lesen Sie hier den Abstract.
Folgende Symptome der Schizophrenie wurden gemessen:
Social Anxiety (SAN), Active Isolation (AIS), Affective Flattening (AFF), Suspiciousness (SUS), Egocentrism (EGC), Living in a Fantasy World (FTW), Alienation (ALN), Apathy (APA), Hostility (HOS), Cognitive Derailment (CDR), Perceptual Aberrations (PER), and Delusional Thinking (DET)
van Kampen (2014)
UV: SUS, AV: EGC
Berechnen Sie die minimale Adjustierungsmenge, um den kausalen Effekt der UV auf die AV zu identifizieren!
Abbildung 14.7 zeigt den DAG von van Kampen (2014) zu den Symptomen der Schizophrenie.
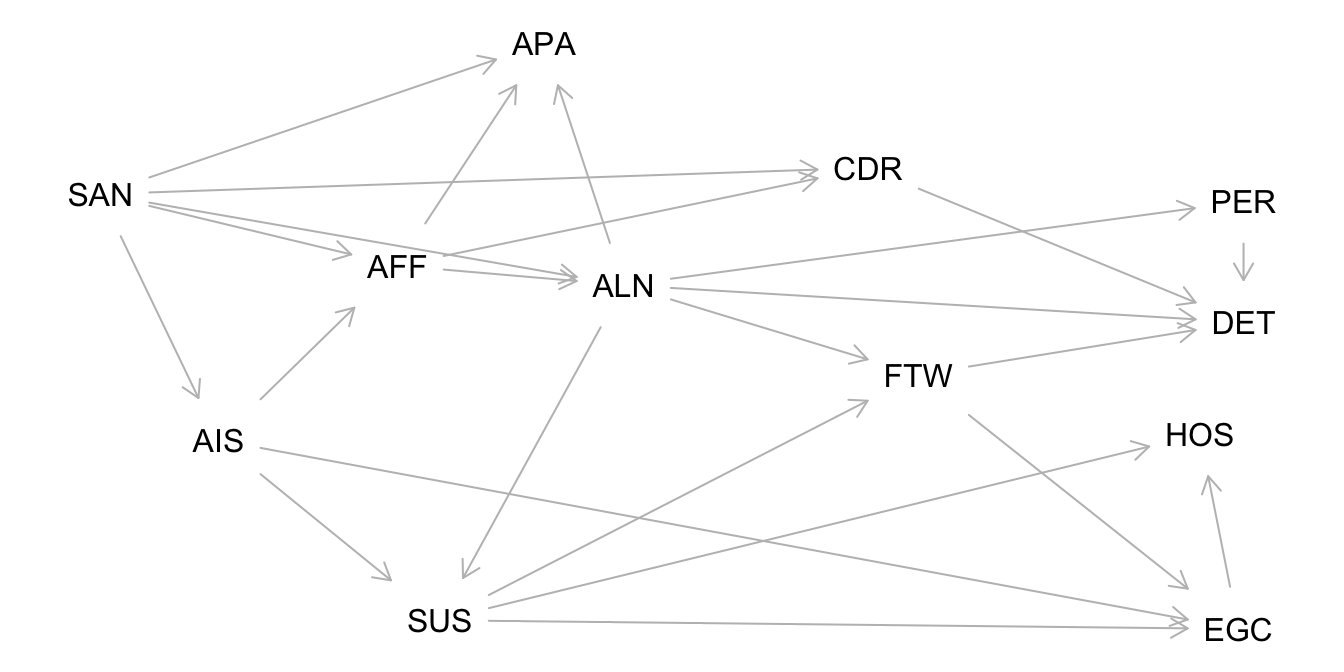
Minimales Adjustment-Set für den totalen Kausaleffekt: {AIS, ALN}
14.6.5 Modelle berechnen
Stellen Sie sich auf Aufgaben ein, in denen Sie Modellparameter berechnen sollen. Orientieren Sie sich an den Aufgaben und Inhalten des Unterrichts.
Prüfungsfragen zu Modellen könnten z.B. sein:
- Geben Sie den Punktschätzer (Median) für den Prädiktor X im Modell Y an!
- Geben Sie ein 89%-HDI für den Parameter X im Modell Y an!
- Geben Sie R-Quadrat an.
- Formulieren Sie ein Interaktionsmodell!
- Welches Modell ist korrekt, um den kausalen Effekt zu modellieren?
- Formulieren Sie ein Modell mit folgenden Prioris …
- Liegt der Effekt X noch im ROPE ?
- Unterscheidet sich die Breite des CI von der Breite des HDI für den Prädiktor X im Modell Y?
- Was verändert sich an den Parametern, wenn Sie die Prädiktoren zentrieren/z-standardisieren?
- …
14.7 Aufgabensammlungen
Folgende Tags auf dem Datenwerk beinhalten relevante Aufgaben3:
Besondere “Prüfungsnähe” könnten diese Sammlungen haben:
14.8 Viel Erfolg bei der Prüfung!
🥳🏆🍀🍀🍀
14.9 —
