13 Die Atome des Kausalität
13.1 Lernsteuerung
13.1.1 Position im Modulverlauf
Abbildung 1.1 gibt einen Überblick zum aktuellen Standort im Modulverlauf.
13.1.2 R-Pakete
Für dieses Kapitel benötigen Sie folgende R-Pakete:
13.1.3 Daten
Wir nutzen den Datensatz Saratoga County; s. Tabelle 12.3. Hier gibt es eine Beschreibung des Datensatzes.
Sie können ihn entweder über die Webseite herunterladen:
SaratogaHouses_path <- "https://vincentarelbundock.github.io/Rdatasets/csv/mosaicData/SaratogaHouses.csv"
d <- read.csv(SaratogaHouses_path)Oder aber über das Paket mosaic importieren:
data("SaratogaHouses", package = "mosaicData")
d <- SaratogaHouses # kürzerer Name, das ist leichter zu tippen13.1.4 Lernziele
Nach Absolvieren des jeweiligen Kapitels sollen folgende Lernziele erreicht sein.
Sie können …
- erklären, wann eine Kausalaussage gegeben eines DAGs berechtigt ist
- erklären, warum ein statistisches Modell ohne Kausalmodell zumeist keine Kausalaussagen treffen kann
- die “Atome” der Kausalität eines DAGs benennen
- “kausale Hintertüren” schließen
13.1.5 Begleitliteratur
Dieses Kapitel vermittelt die Grundlagen der Kausalinferenz mittels graphischer Modelle. Ähnliche Darstellungen wie in diesem Kapitel findet sich bei Rohrer (2018).
13.2 Kollision
13.2.1 Kein Zusammenhang von Intelligenz und Schönheit (?)
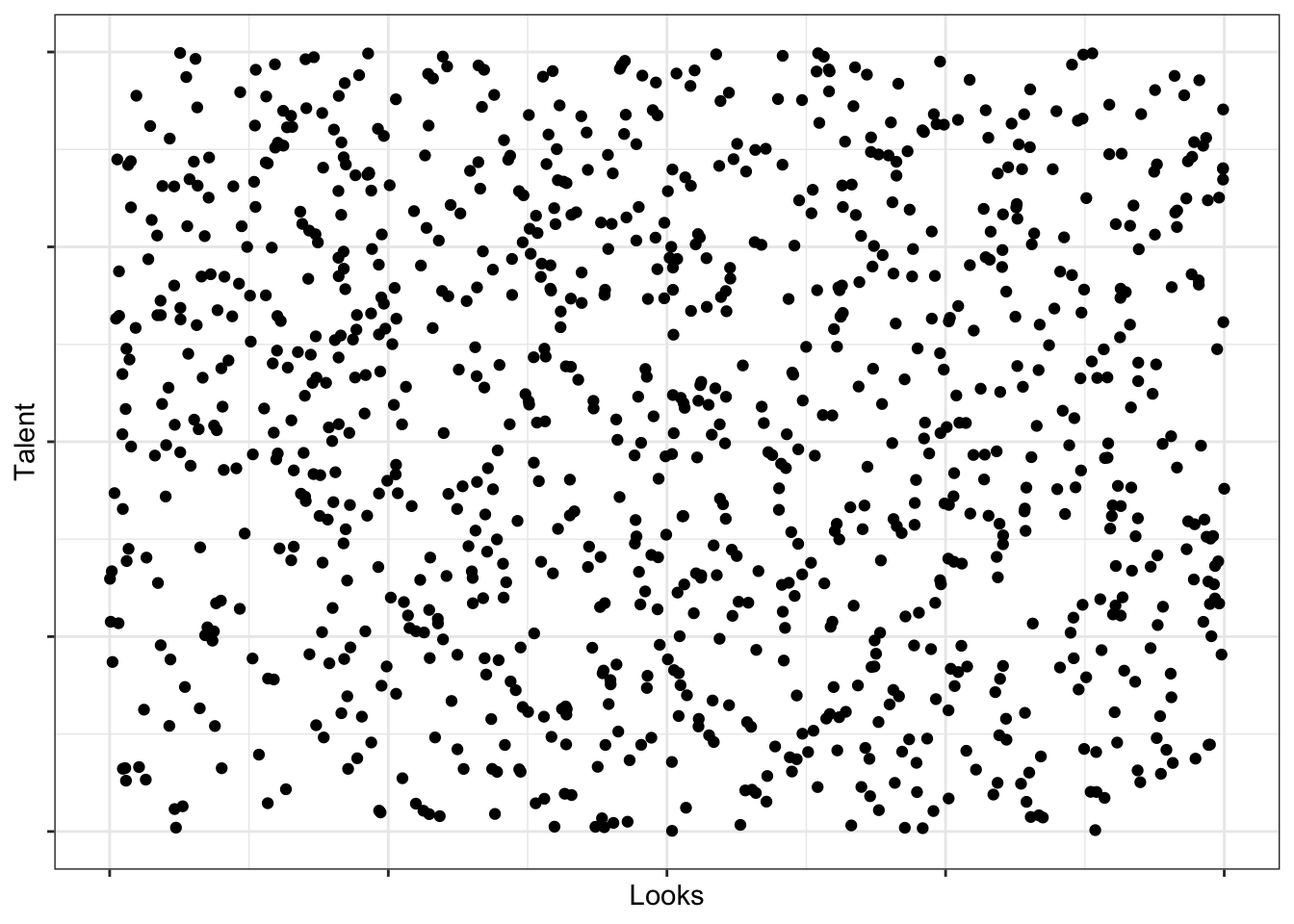
Zumindest findet sich in folgenden Daten kein Zusammenhang von Intelligenz (talent) und Schönheit (looks), wie Abbildung 13.1 illustriert. Für geringe Intelligenzwerte gibt es eine breites Spektrum von Schönheitswerten und für hohe Intelligenzwerte sieht es genauso aus.
13.2.2 Aber Ihre Dates sind entweder schlau oder schön
Seltsamerweise beobachten Sie, dass die Menschen, die Sie daten (Ihre Dates), entweder schön sind oder schlau - aber seltens beides gleichzeitig (schade), s. Abbildung 13.2.
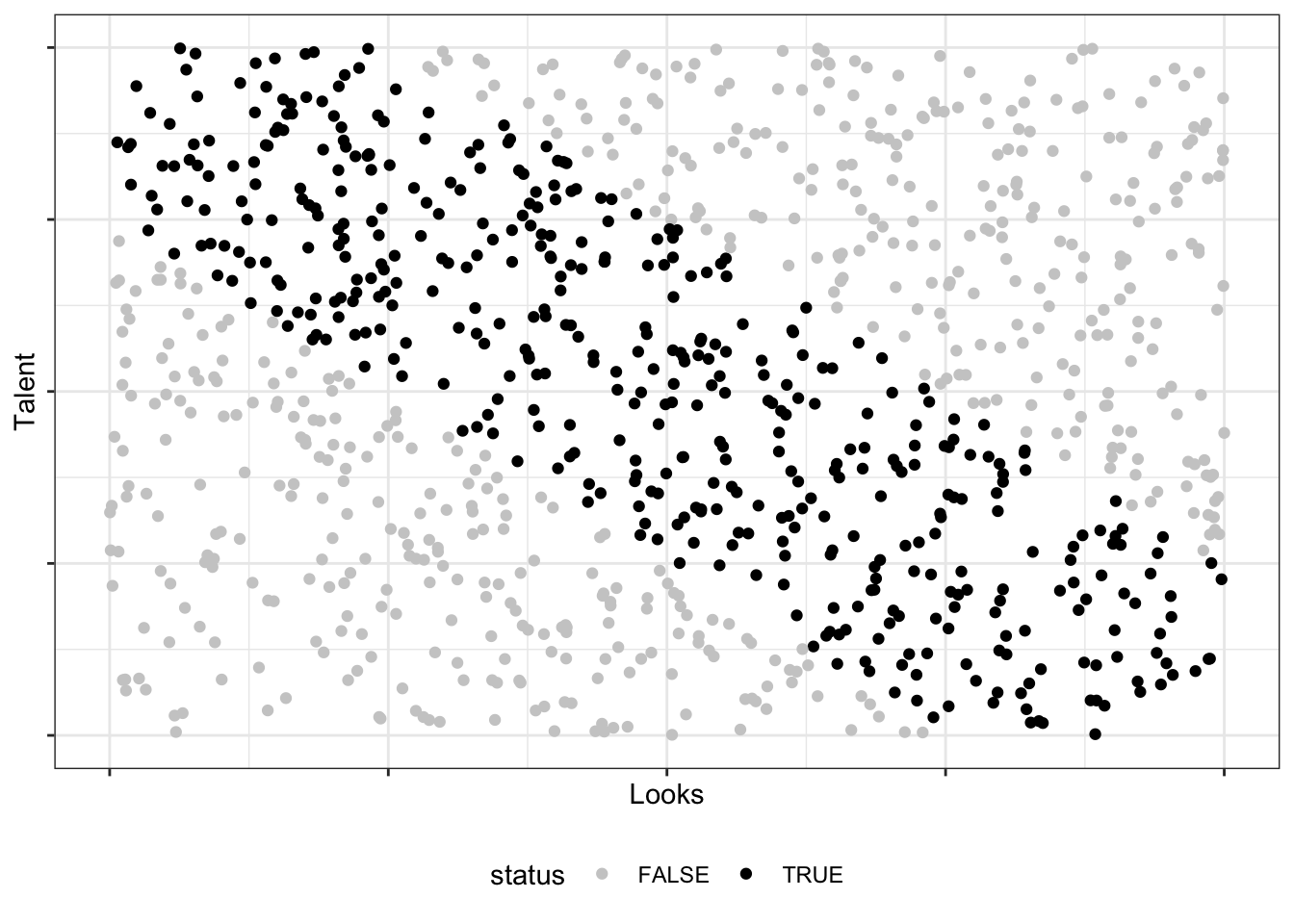
Wie kann das sein?
13.2.3 DAG zur Rettung
🦹 🦸
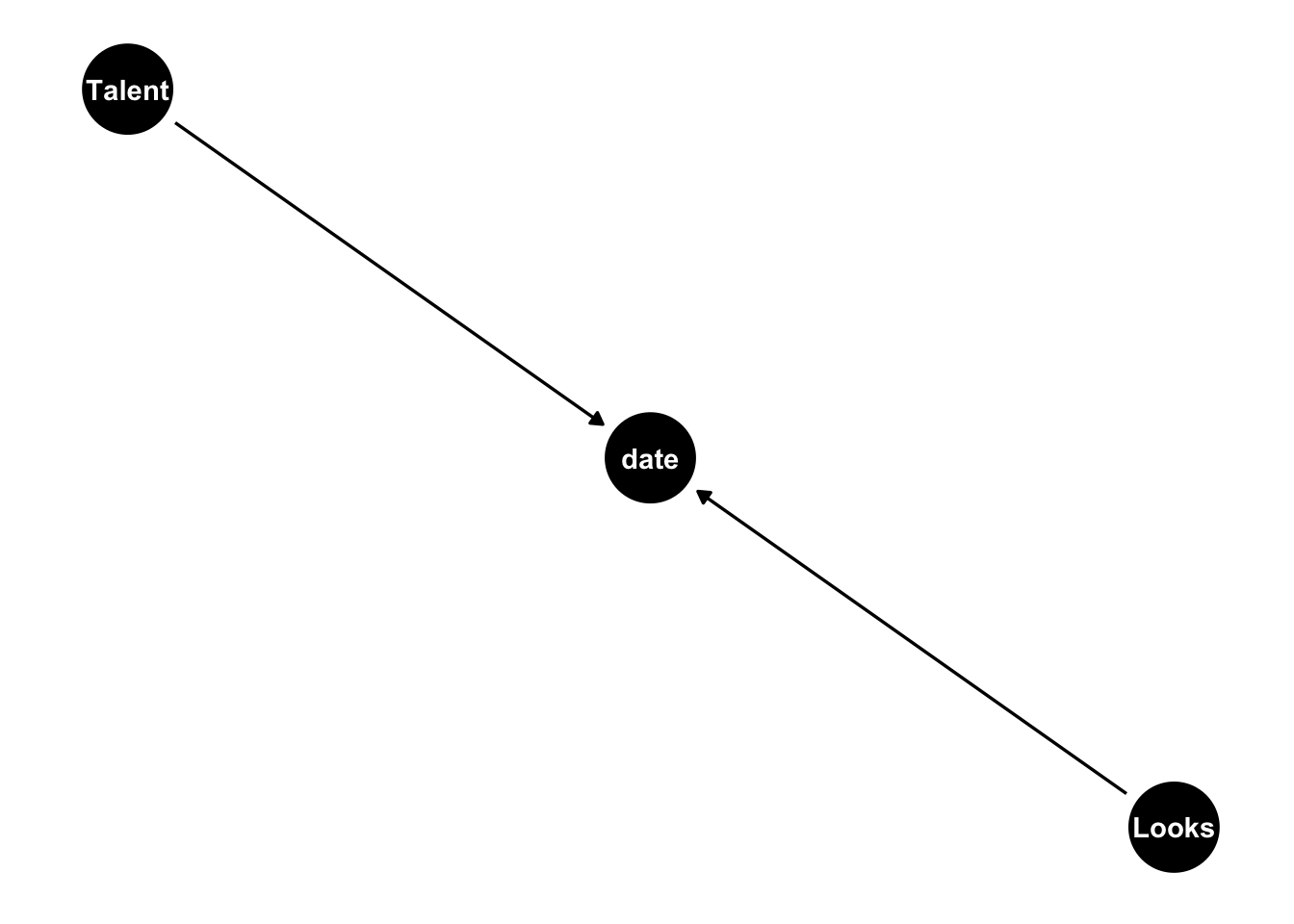
Der DAG in Abbildung 13.3 bietet eine rettende Erklärung.
Eine ähnliche Visualisierung des gleichen Sachverhalts zeigt Abbildung 13.4.

13.2.4 Was ist eine Kollision?
Definition 13.1 (Kollision) Als Kollision (Kollisionsverzerrung, Auswahlverzerrung, engl. collider) bezeichnet man einen DAG, bei dem eine Wirkung zwei Ursachen hat (eine gemeinsame Wirkung zweier Ursachen) (Pearl et al., 2016, p. 40). \(\square\)
Kontrolliert man die Wirkung m, so entsteht eine Scheinkorrelation zwischen den Ursachen x und y. Kontrolliert man die Wirkung nicht, so entsteht keine Scheinkorrelation zwischen den Ursachen, s. Abbildung 13.3, vgl. Rohrer (2018).
Man kann also zu viele oder falsche Prädiktoren einer Regression hinzufügen, so dass die Koeffizienten nicht die kausalen Effekte zeigen, sondern durch Scheinkorrelation verzerrte Werte.
🙅♀️ Kontrollieren Sie keine Kollisionsvariablen. \(\square\)
13.2.5 Einfaches Beispiel zur Kollision
In der Zeitung Glitzer werden nur folgende Menschen gezeigt:
- Schöne Menschen 🪞
- Reiche Menschen 🤑
Sehen wir davon aus, dass Schönheit und Reichtum unabhängig voneinander sind.
Übungsaufgabe 13.1 Wenn ich Ihnen sage, dass Don nicht schön ist, aber in der Glitzer häufig auftaucht, was lernen wir dann über seine finanzielle Situation?1 \(\square\)
“Ich bin schön, unglaublich schön, und groß, großartig, tolle Gene!!!” 🧑
13.2.6 Noch ein einfaches Beispiel zur Kollision
“So langsam check ich’s!” 🧑2
Sei Z = X + Y, wobei X und Y unabhängig sind.
Wenn ich Ihnen sage, X = 3, lernen Sie nichts über Y, da die beiden Variablen unabhängig sind Aber: Wenn ich Ihnen zuerst sage, Z = 10, und dann sage, X = 3, wissen Sie sofort, was Y ist (Y = 7).
Also: X und Y sind abhängig, gegeben Z: \(X \not\perp \!\!\! \perp Y \,|\, Z\).3
13.2.7 Durch Kontrollieren entsteht eine Verzerrung bei der Kollision
Abbildung 13.3 zeigt: Durch Kontrollieren entsteht eine Kollision, eine Scheinkorrelation zwischen den Ursachen.
Kontrollieren kann z.B. bedeuten:
-
Stratifizieren: Aufteilen von
datein zwei Gruppen und dann Analyse des Zusammenhangs vontalentundlooksin jeder Teilgruppe vondate -
Kontrollieren mit Regression: Durch Aufnahme von
dateals Prädiktor in eine Regression zusätzlich zulooksmittalentals Prädikotr
Ohne Kontrolle von date entsteht keine Scheinkorrelation zwischen Looks und Talent. Der Pfad (“Fluss”) von Looks über date nach Talent ist blockiert.
Kontrolliert man date, so öffnet sich der Pfad Looks -> date -> talent und die Scheinkorrelation entsteht: Der Pfad ist nicht mehr “blockiert”, die Korrelation kann “fließen” - was sie hier nicht soll, denn es handelt sich um Scheinkorrelation.
Das Kontrollieren von date geht zumeist durch Bilden einer Auswahl einer Teilgruppe von sich.
13.2.8 IQ, Fleiss und Eignung fürs Studium
Sagen wir, über die Eignung für ein Studium würden nur (die individuellen Ausprägungen) von Intelligenz (IQ) und Fleiss entscheiden, s. den DAG in Abbildung 13.5.
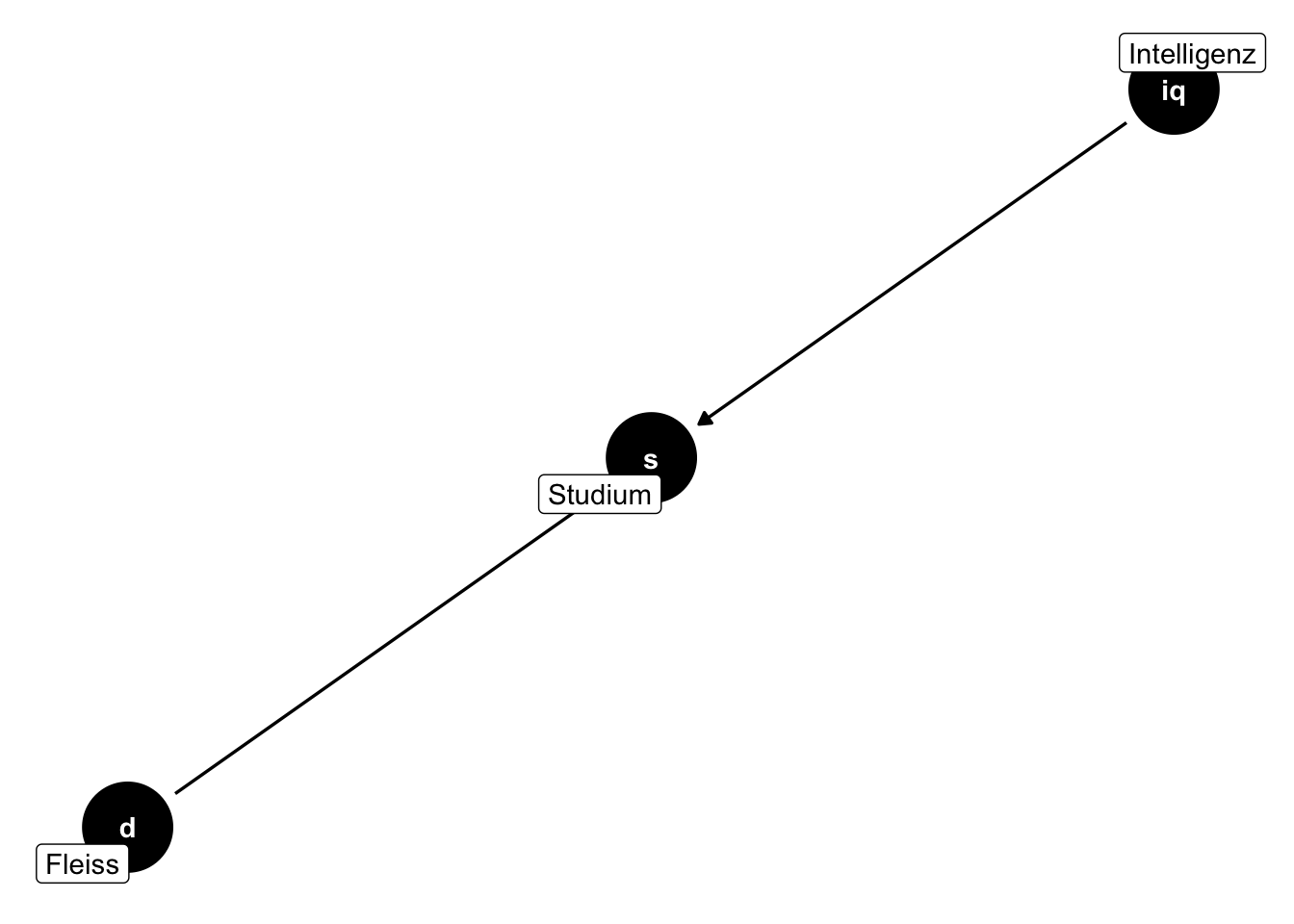
Bei positiver eignung wird ein Studium aufgenommen (studium = 1) ansonsten nicht (studium = 0).
eignung (fürs Studium) sei definiert als die Summe von iq und fleiss, plus etwas Glück, s. Listing 13.1.
set.seed(42) # Reproduzierbarkeit
N <- 1e03
d_eignung <-
tibble(
iq = rnorm(N), # normalverteilt mit MW=0, sd=1
fleiss = rnorm(N),
glueck = rnorm(N, mean = 0, sd = .1),
eignung = 1/2 * iq + 1/2 * fleiss + glueck,
# nur wer geeignet ist, studiert (in unserem Modell):
studium = ifelse(eignung > 0, 1, 0)
)Laut unserem Modell setzt sich Eignung zur Hälfte aus Intelligenz und zur Hälfte aus Fleiss zusammen, plus etwas Glück.
13.2.9 Schlagzeile “Fleiß macht blöd!”
Eine Studie untersucht den Zusammenhang von Intelligenz (iq) und Fleiß (f) bei Studentis (s). Ergebnis: Ein negativer Zusammenhang!?
Berechnen wir das “Eignungsmodell”, aber nur mit Studis (studium == 1, also ohne Nicht-Studis), s. Tabelle 13.1.
| Parameter | 95% HDI |
|---|---|
| (Intercept) | [ 0.70, 0.86] |
| fleiss | [-0.53, -0.36] |
Abbildung 13.6 zeigt das Modell und die Daten.
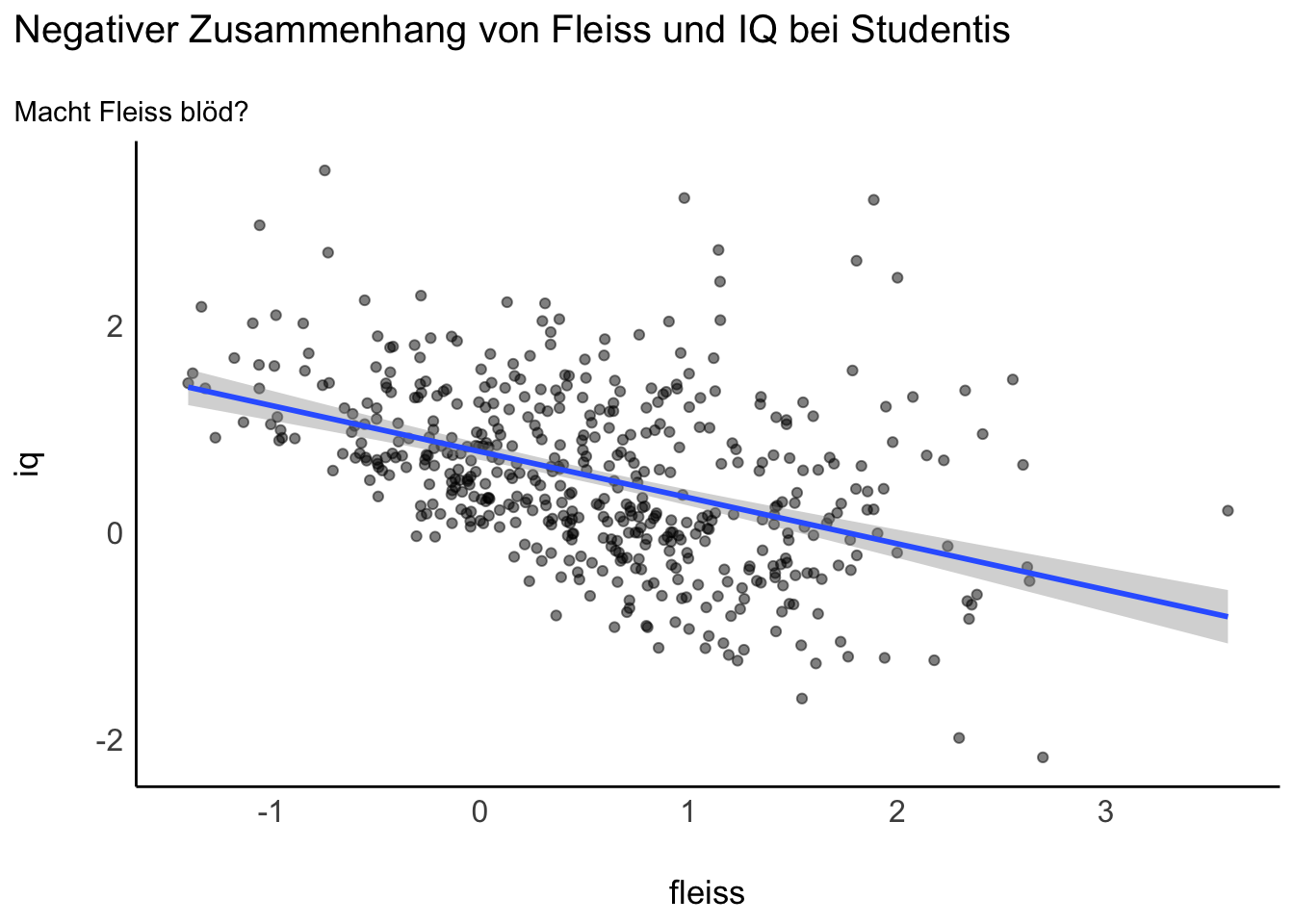
IQ ist nicht unabhängig von Fleiß in unseren Daten, sondern abhängig. Nichtwissenschaftliche Berichte, etwa in einigen Medien, greifen gerne Befunde über Zusammenhänge auf und interpretieren die Zusammenhänge – oft vorschnell – als kausal.4
13.2.10 Kollisionsverzerrung nur bei Stratifizierung
Definition 13.2 (Stratifizieren) Durch Stratifizieren wird eine Stichprobe in (homogene) Untergruppen unterteilt (sog. Strata). \(\square\)
Nur durch das Stratifizieren (Aufteilen in Subgruppen, Kontrollieren, Adjustieren) tritt die Scheinkorrelation auf, s. Abbildung 13.7.
Ohne Stratifizierung tritt keine Scheinkorrelation auf. Mit Stratifizierung tritt Scheinkorrelation auf.

Wildes Kontrollieren einer Variablen - Aufnehmen in die Regression - kann genausog ut schaden wie nützen.
Nur Kenntnis des DAGs verrät die richtige Entscheidung: ob man eine Variable kontrolliert oder nicht.
Nimmt man eine Variable als zweiten Prädiktor auf, so “kontrolliert” man diese Variable. Das Regressiongewicht des ersten Prädiktors wird “bereinigt” um den Einfluss des zweiten Prädiktors; insofern ist der zweite Prädiktor dann “kontrolliert”.
13.2.11 Einfluss von Großeltern und Eltern auf Kinder
Wir wollen hier den (kausalen) Einfluss der Eltern E und Großeltern G auf den Bildungserfolg der Kinder K untersuchen.
Wir nehmen folgende Effekte an:
- indirekter Effekt von
GaufK: \(G \rightarrow E \rightarrow K\) - direkter Effekt von
EaufK: \(E \rightarrow K\) - direkter Effekt von
GaufK: \(G \rightarrow K\)
Wir sind v.a. interessiert an \(G \rightarrow K\), dem direkten kausalen Effekt von Großeltern auf ihre Enkel, s. Abbildung 13.8, \(G \rightarrow K\).
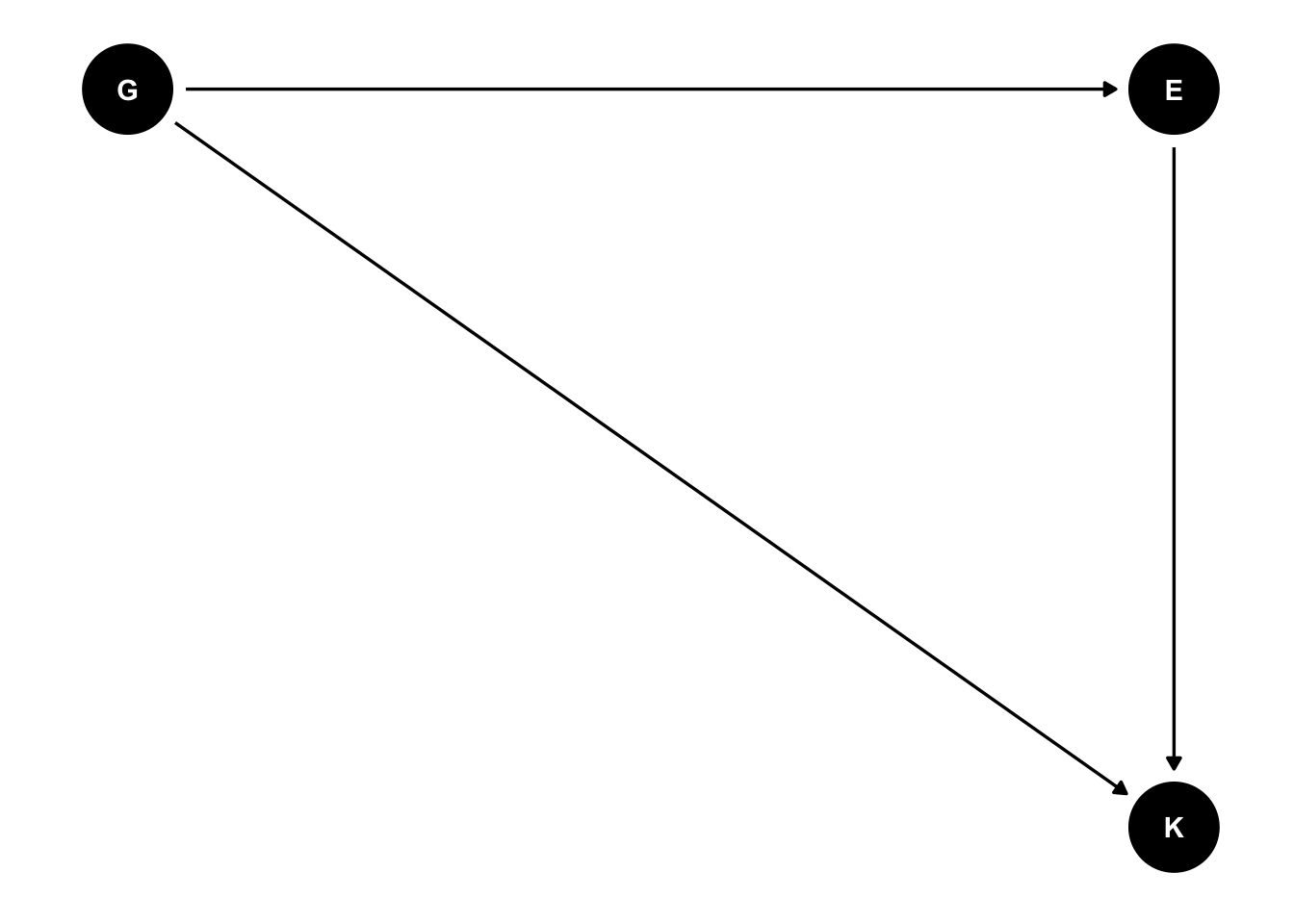
Aber was ist, wenn wir vielleicht eine unbekannte Variable übersehen haben? (S. nächster Abschnitt). 👻
13.2.12 Der Gespenster-DAG
👻 Es gibt “unheilbare” DAGs, nennen wir sie “Gespenster-DAGs”, in denen es nicht möglich ist, einen (unverzerrten) Kausaleffekt zu bestimmen, s. Abbildung 13.9. Letztlich sagt uns der DAG bzw. unsere Analyse zum DAG: “Deine Theorie ist nicht gut, zurück an den Schreibtisch und denk noch mal gut nach. Oder sammele mehr Daten.”

U könnte ein ungemessener Einfluss sein, der auf E und K wirkt, etwa Nachbarschaft. Die Großeltern wohnen woanders (in Spanien), daher wirkt die Nachbarschaft der Eltern und Kinder nicht auf sie. E ist sowohl für G als auch für U eine Wirkung, also eine Kollisionsvariable auf diesem Pfad. Wenn wir E kontrollieren, wird es den Pfad \(G \rightarrow K\) verzerren, auch wenn wir niemals U messen.
Die Sache ist in diesem Fall chancenlos. Wir müssen diesen DAG verloren geben, McElreath (2020), S. 180; ein Gespenster-DAG. 👻
13.3 Die Hintertür schließen
Definition 13.3 (Hintertür) Eine “Hintertür” ist ein nicht-kausaler Pfad zwischen einer UV und einer AV. Ein Hintertürpfad entsteht, wenn es eine alternative Route über eine oder mehrere Variable gibt, die UV mit der AV verbindet. Dieser Pfad verzerrt die Schätzwerte des kausalen Einflusses, wenn er nicht kontrolliert wird. \(\square\)
13.3.1 Zur Erinnerung: Konfundierung
Forschungsfrage: Wie groß ist der (kausale) Einfluss der Schlafzimmerzahl auf den Verkaufspreis des Hauses?
a: livingArea, b: bedrooms, p: prize
UV: b, AV: p
Das Kausalmodell ist in Abbildung 13.10 dargestellt.

Im Regressionsmodell p ~ b wird der kausale Effekt verzerrt sein durch die Konfundierung mit a. Der Grund für die Konfundierung sind die zwei Pfade zwischen b und p:
- \(b \rightarrow p\)
- \(b \leftarrow a \rightarrow p\)
Beide Pfade erzeugen (statistische) Assoziation zwischen b und p. Aber nur der erste Pfad ist kausal; der zweite ist nichtkausal. Gäbe es nur nur den zweiten Pfad und wir würden b ändern, so würde sich p nicht ändern.
13.3.2 Gute Experimente zeigen den echten kausalen Effekt
Abbildung 13.11 zeigt eine erfreuliche Situation: Die “Hintertür” zu unserer UV (Zimmerzahl) ist geschlossen!
Ist die Hintertür geschlossen - führen also keine Pfeile in unserer UV - so kann eine Konfundierung ausgeschlossen werden.

Die “Hintertür” der UV (b) ist jetzt zu! Der einzig verbleibende, erste Pfad ist der kausale Pfad und die Assoziation zwischen b und p ist jetzt komplett kausal.
Eine berühmte Lösung, den kausalen Pfad zu isolieren, ist ein (randomisiertes, kontrolliertes5) Experiment. Wenn wir den Häusern zufällig (randomisiert) eine Anzahl von Schlafzimmern (b) zuweisen könnten (unabhängig von ihrer Quadratmeterzahl, a), würde sich der Graph so ändern. Das Experiment entfernt den Einfluss von a auf b. Wenn wir selber die Werte von b einstellen im Rahmen des Experiments, so kann a keine Wirkung auf b haben. Damit wird der zweite Pfad, \(b \leftarrow a \rightarrow p\) geschlossen (“blockiert”).
Die Stärke von (gut gemachten) Experimente ist, dass sie kausale Hintertüren schließen. Damit erlauben sie (korrekte) Kausalaussagen. \(\square\)
13.3.3 Hintertür schließen auch ohne Experimente
Konfundierende Pfade zu blockieren zwischen der UV und der AV nennt man auch die Hintertür schließen (backdoor criterion). Wir wollen die Hintertüre schließen, da wir sonst nicht den wahren, kausalen Effekt bestimmen können.
Zum Glück gibt es neben Experimenten noch andere Wege, die Hintertür zu schließen, wie die Konfundierungsvariable a in eine Regression mit aufzunehmen.
Kontrollieren Sie Konfundierer, um kausale Hintertüren zu schließen. \(\square\)
Warum blockt das Kontrollieren von aden Pfad \(b \leftarrow a \rightarrow p\)? Stellen Sie sich den Pfad als eigenen Modell vor. Sobald Sie a kennen, bringt Ihnen Kenntnis über b kein zusätzliches Wissen über p. Wissen Sie hingegen nichts über a, lernen Sie bei Kenntnis von b auch etwas über p. Konditionieren ist wie “gegeben, dass Sie a schon kennen…”.
\(b \perp \!\!\! \perp p \,|\,a\)
13.4 Die vier Atome der Kausalanalyse
Abbildung 13.12 stellt die vier “Atome” der Kausalinferenz dar. Mehr gibt es nicht! Kennen Sie diese vier Grundbausteine, so können Sie jedes beliebige Kausalsystem (DAG) entschlüsseln.
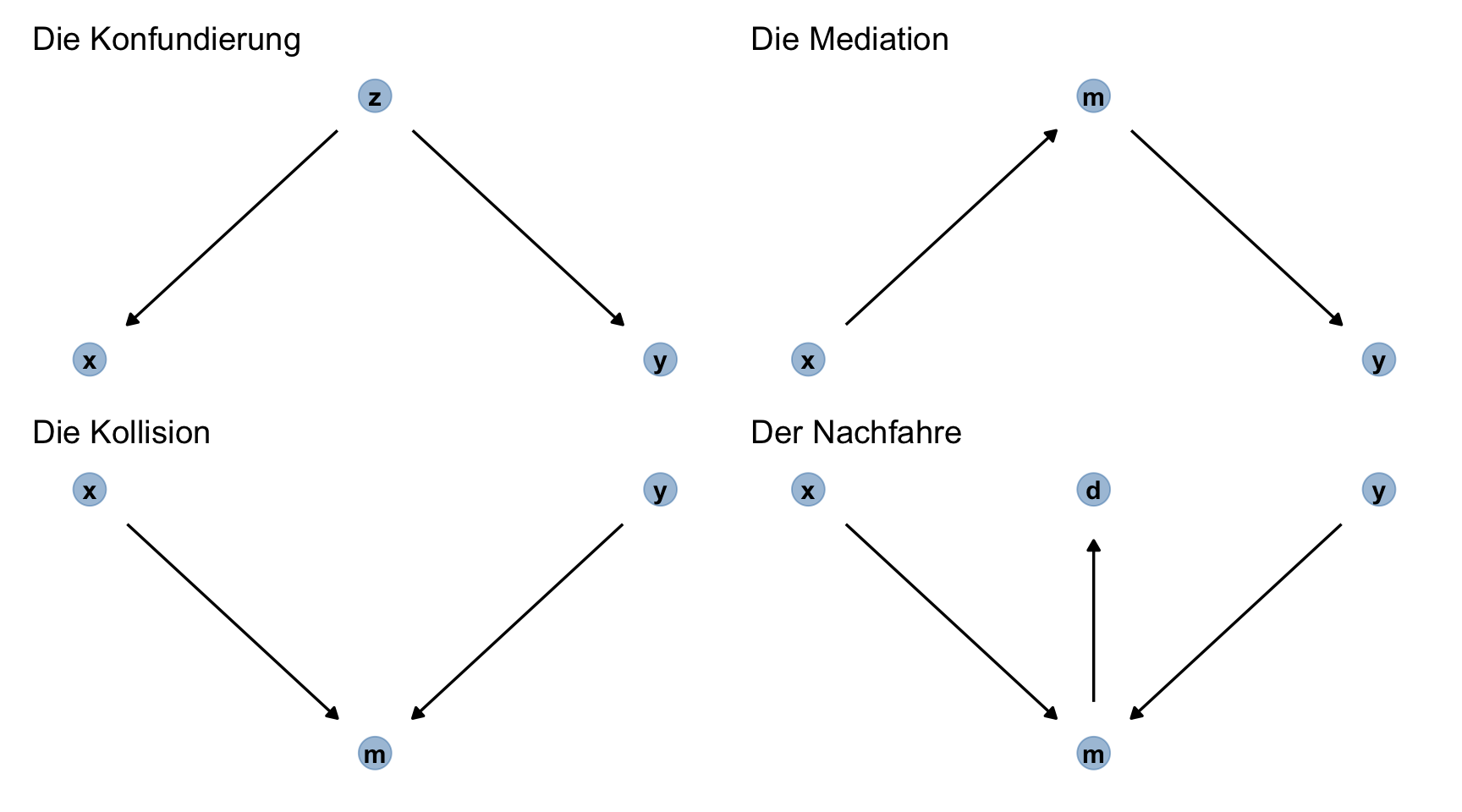
13.4.1 Mediation
Definition 13.4 (Mediator) Einen Pfad mit drei Knoten (Variablen), die über insgesamt zwei Kanten verbunden sind, wobei die Pfeile von UV zu Mediator und von Mediator zur AV zeigen, nennt man Mediation. Der Mediator ist die Variable zwischen UV und AV [Pearl et al. (2016); p. 38]. \(\square\)
Die Mediation (synonym: Wirkkette, Rohr, Kette, chain) beschreibt Pfade, in der die Kanten (eines Pfades) die gleiche Wirkrichtung haben: \(x \rightarrow m \rightarrow y\). Anders gesagt: Eine Mediation ist eine Kausalabfolge der Art \(x \rightarrow m \rightarrow y\), s. Abbildung 13.13. Die Variable in der Mitte \(m\) der Kette wird auch Mediator genannt, weil sei die Wirkung von X auf Y “vermittelt” oder überträgt. Die Erforschung von Mediation spielt eine recht wichtige Rolle in einigen Wissenschaften, wie der Psychologie.
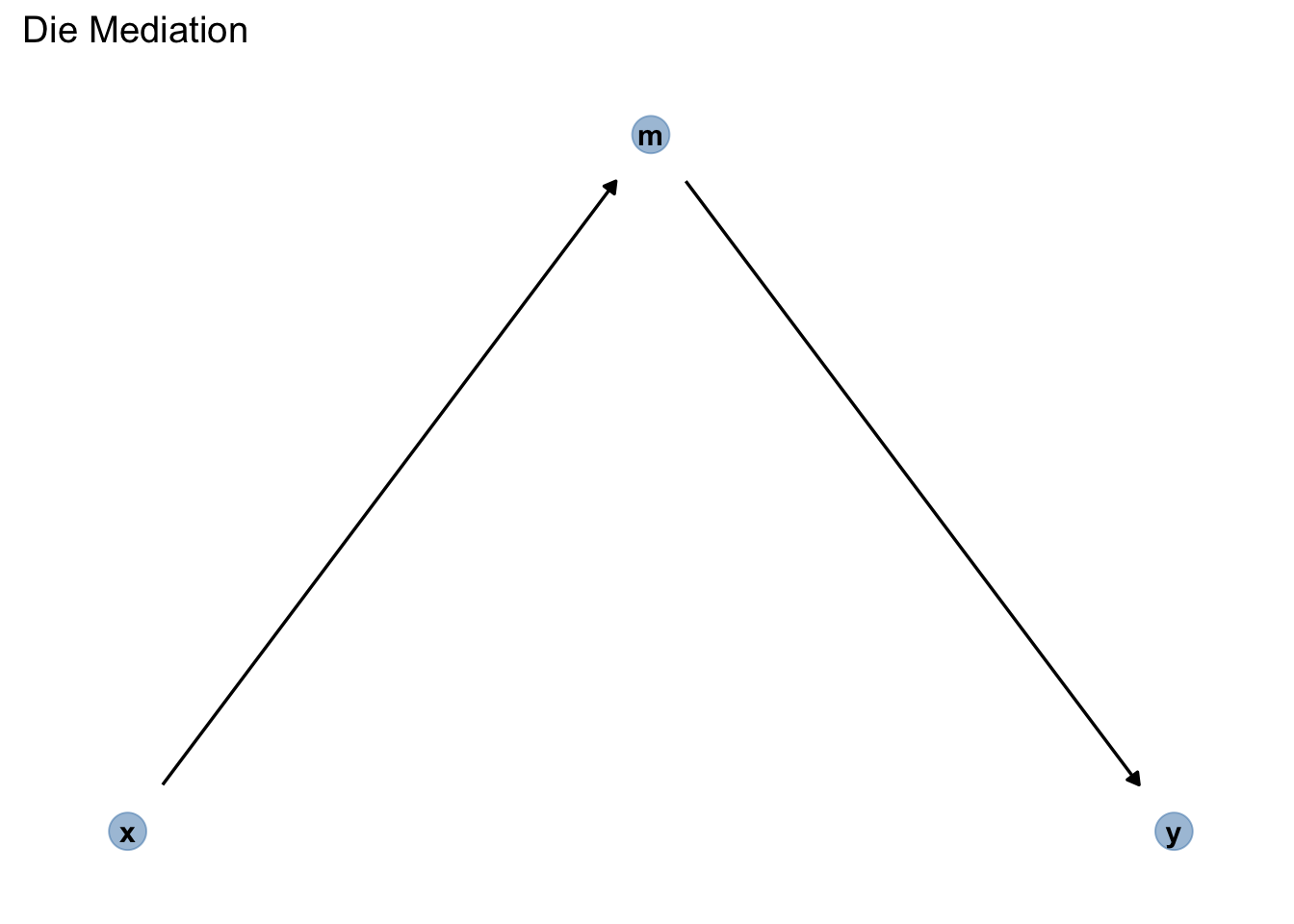
Beispiel 13.1 (Mediator kontrollieren?) Sollte man den Mediator m in Abbildung 13.13 kontrollieren, wenn man den Kausaleffekt von x auf y schätzen möchte?6 \(\square\)
Ohne Kontrollieren ist der Pfad offen: Die Assoziation “fließt” den Pfad entlang (in beide Richtungen). Kontrollieren blockt (schließt) die Kette (genau wie bei der Gabel).
Kontrollieren Sie den Mediator nicht. Der Pfad über den Mediator ist ein “echter” Kausalpfad, keine Scheinkorrelation. \(\square\)
Das Kontrollieren eines Mediators ist ein Fehler, wenn man am gesamten (totalen) Kausaleffekt von UV zu AV interessiert ist. \(\square\)
Es kann auch angenommen werden, dass der Mediator nicht der einzige Weg von X zu Y ist, s. Abbildung 13.14. In Abbildung 13.14 gibt es zwei kausale Pfade von X zu Y: \(x\rightarrow m \rightarrow y\) und \(x \rightarrow y\).
Definition 13.5 (Kausaleffekt) Gibt es eine (von (praktisch) Null verschiedene) kausale Assoziation der UV auf die AV, so hängt die AV von der UV (kausal) ab. Man spricht von einem Kausaleffekt (der UV auf die AV). \(\square\)
Definition 13.6 (Totaler Effekt) Die Summe der Effekte aller (kausalen) Pfade von UV zu AV nennt man den totalen (kausalen) Effekt. \(\square\)
Definition 13.7 (Indirekter Effekt) Den (kausalen) Effekt über den Mediatorpfad (von \(X\) über \(M\) zu \(Y\)) nennt man den indirekten (kausalen) Effekt. \(\square\)
Definition 13.8 (Direkter Effekt) Ein Effekt, der nur aus dem Pfad \(x\rightarrow y\) besteht, also ohne keine Zwischenglieder, nennt man in Abgrenzung zum indirekten Effekt, direkten (kausalen) Effekt. \(\square\)

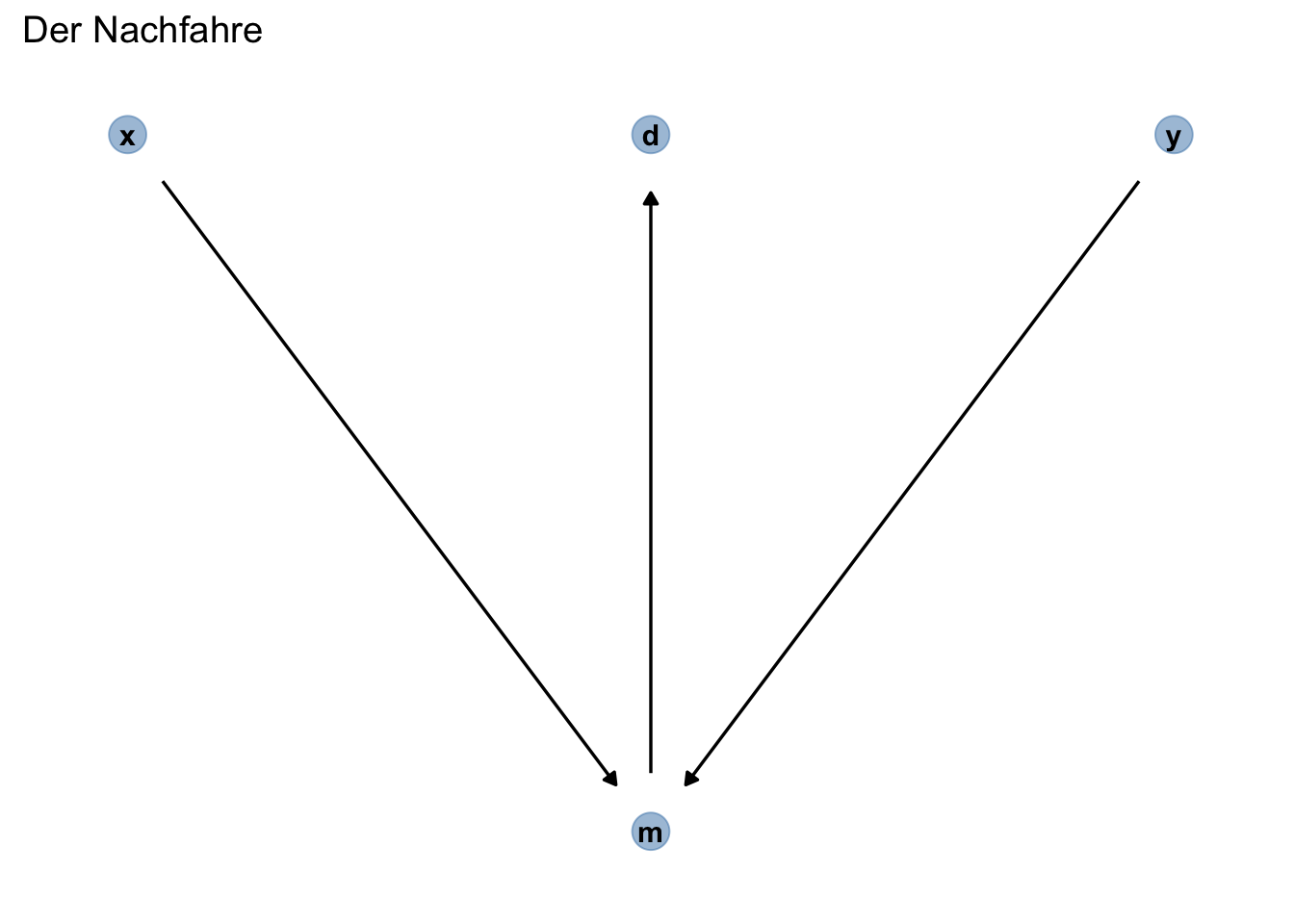
13.4.2 Der Nachfahre
Definition 13.9 (Nachfahre) Ein Nachfahre (engl. descendent) ist eine Variable, die von einer anderen Variable beeinflusst7 wird, s. Abbildung 13.15. \(\square\)
Kontrolliert man einen Nachfahren d, so kontrolliert man damit zum Teil den Vorfahren (die Ursache), m. Der Grund ist, dass d Information beinhaltet über m. Hier wird das Kontrollieren von d den Pfad von x nach y teilweise öffnen, da m eine Kollisionsvariable ist.
13.4.3 Kochrezept zur Analyse von DAGs 👨🍳
Wie kompliziert ein DAG auch aussehen mag, er ist immer aus diesen vier Atomen aufgebaut.
Hier ist ein Rezept, das garantiert, dass Sie welche Variablen Sie kontrollieren sollten und welche nicht: 📄
- Listen Sie alle Pfade von UV (
X) zu AV (Y) auf. - Beurteilen Sie jeden Pfad, ob er gerade geschlossen oder geöffnet ist.
- Beurteilen Sie für jeden Pfad, ob er ein Hintertürpfad ist (Hintertürpfade haben einen Pfeil, der zur UV führt).
- Wenn es geöffnete Hinterpfade gibt, prüfen Sie, welche Variablen mann kontrollieren muss, um den Pfad zu schließen (falls möglich).
13.5 Schließen Sie die Hintertür (wenn möglich)!
13.5.1 Hintertür: ja oder nein?
13.5.1.1 Fall 1: x->
\(\boxed{X \rightarrow}\)
Alle Pfade, die von der UV (X) wegführen, sind entweder “gute” Kausalpfade oder automatisch geblockte Nicht-Kausal-Pfade. In diesem Fall müssen wir nichts tun.8
13.5.1.2 Fall 2: ->x
\(\boxed{\rightarrow X}\)
Alle Pfade, die zur UV hinführen, sind immer Nicht-Kausal-Pfade, Hintertüren. Diese Pfade können offen sein, dann müssen wir sie schließen. Sie können auch geschlossen sein, dann müssen wir nichts tun.
Schließen Sie immer offene Hintertüren, um Verzerrungen der Kausaleffekte zu verhinden. \(\square\)
13.5.2 bsp1
UV: \(X\), AV: \(Y\), drei Kovariaten (A, B, C) und ein ungemessene Variable, U
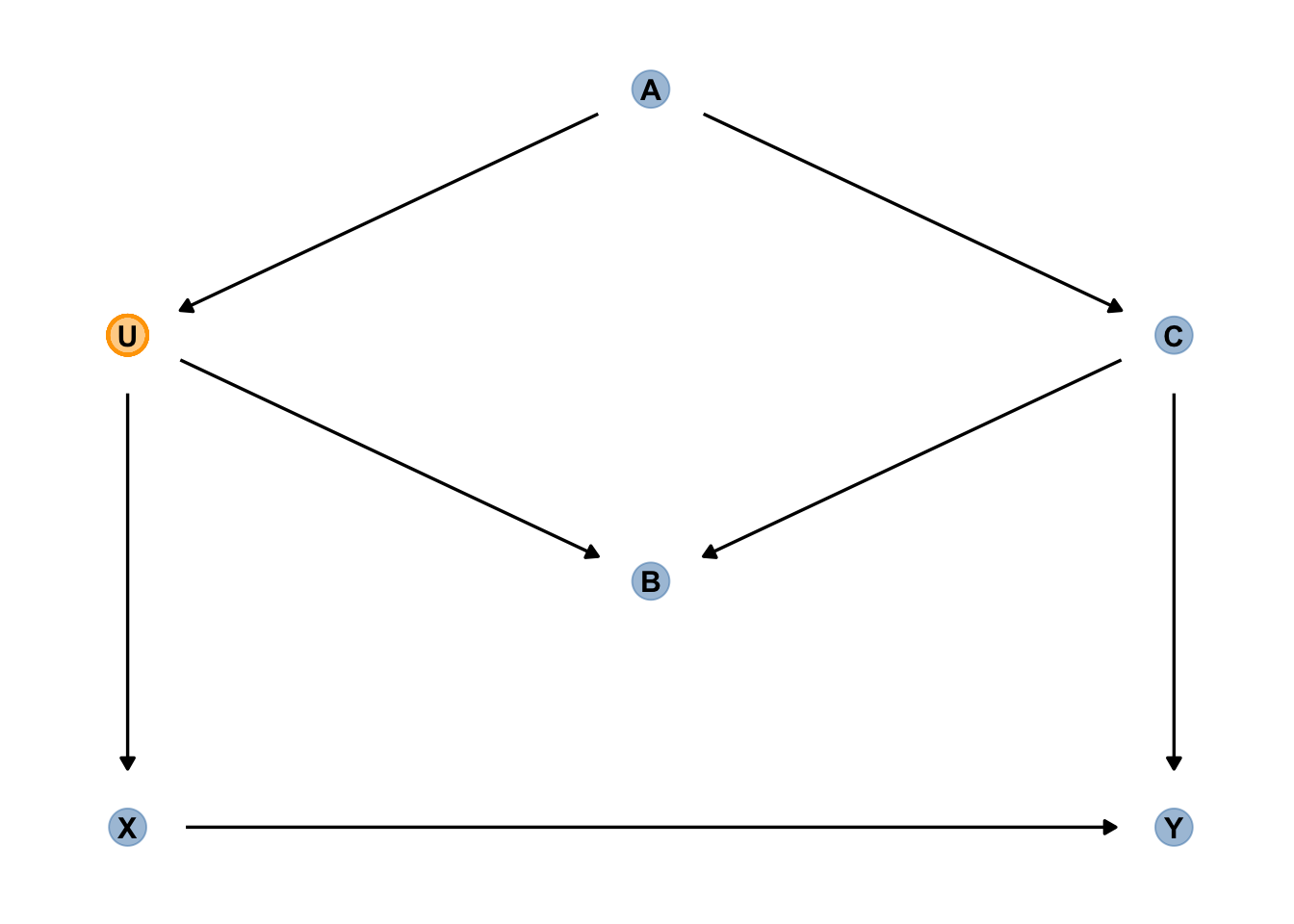
Es gibt zwei Hintertürpfade in Abbildung 13.16:
- \(X \leftarrow U \leftarrow A \rightarrow C \rightarrow Y\), offen
- \(X \leftarrow U \rightarrow B \leftarrow C \rightarrow Y\), geschlossen
Kontrollieren von \(A\) oder (auch) \(C\) schließt die offene Hintertür.
13.5.3 Schließen Sie die Hintertür (wenn möglich)!, bsp2
S. DAG in Abbildung 13.17: UV: \(W\), AV: \(D\)

Kontrollieren Sie diese Variablen, um die offenen Hintertüren zu schließen:
- entweder \(A\) und \(M\)
- oder \(S\)
Details finden sich bei McElreath (2020) oder Kurz (2021), S. 188.
13.5.4 Implizierte bedingte Unabhängigkeiten von bsp2
Auch wenn die Daten nicht sagen können, welcher DAG der richtige ist, können wir zumindest lernen, welcher DAG falsch ist. Die vom Modell implizierten bedingten Unabhängigkeiten geben uns Möglichkeiten, zu prüfen, ob wir einen DAG verwerfen (ausschließen) können. Bedingten Unabhängigkeit zwischen zwei Variablen sind Variablen, die nicht assoziiert (also stochastisch unabhängig) sind, wenn wir eine bestimmte Menge an Drittvariablen kontrollieren.
bsp2 impliziert folgende bedingte Unabhängigkeiten:
## A _||_ W | S
## D _||_ S | A, M, W
## M _||_ W | S13.6 Fazit
13.6.1 Ausstieg
📺 Musterlösung für eine DAG-Prüfungsaufgabe
📺 Musterlösung für schwierige DAG-Prüfungsaufgaben
Beispiel 13.2 (PMI zum heutigen Stoff) Der Kreativitätsforscher Edward de Bono hat verschiedene “Denkmethoden” vorgestellt, die helfen sollen, Probleme besser zu lösen. Eine Methode ist die “PMI-Methode”. PMI steht für Plus, Minus, Interessant. Bei Plus und Minus soll man eine Bewertung von Positiven bzw. Negativen bzgl. eines Sachverhaltes anführen. Bei Interessant verzichtet man aber explizit auf eine Bewertung (im Sinne von “gut” oder “schlecht”) und fokussiert sich auf Interessantes, Überraschendes, Bemerkenswertes.
Führen Sie die PMI-Methode zum heutigen Stoff durch!
- Plus: Was fanden Sie am heutigen Stoff gut, sinnvoll, nützlich?
- Minus: Was finden Sie am heutigen Stoff nicht gut, sinvoll, nützlich?
- Interessant: Was finden Sie am heutigen Stoff bemerkenswert, interessant, nachdenkenswert?
Reichen Sie die Antworten an der von der Lehrkraft angezeigten Stelle ein! \(\square\)
13.6.2 Zusammenfassung
Wie (und sogar ob) Sie statistische Ergebnisse (z.B. eines Regressionsmodells) interpretieren können, hängt von der epistemologischen Zielrichtung der Forschungsfrage ab:
- Bei deskriptiven Forschungsfragen können die Ergebnisse (z.B. Regressionskoeffizienten) direkt interpretiert werden. Z.B. “Der Unterschied zwischen beiden Gruppen beträgt etwa …”. Allerdings ist eine kausale Interpretation nicht zulässig.
- Bei prognostischen Fragestellungen (Vorhersagen) spielen die Modellkoeffizienten keine Rolle, stattdessen geht es um vorhergesagten Werte, \(\hat{y}_i\), z.B. auf Basis der PPV. Kausalaussagen sind zwar nicht möglich, aber auch nicht von Interesse.
- Bei kausalen Forschungsfragen dürfen die Modellkoeffizienten nur auf Basis eines Kausalmodells (DAG) oder eines (gut gemachten) Experiments interpretiert werden.
Modellkoeffizienten ändern sich (oft), wenn man Prädiktoren zum Modell hinzufügt oder wegnimmt. Entgegen der verbreiteten Annahme ist es falsch, möglichst viele Prädiktoren in das Modell aufzunehmen, wenn das Ziel eine Kausalaussage ist. Kenntnis der “kausalen Atome” ist Voraussetzung zur Ableitung von Kausalschlüsse in Beobachtungsstudien.
13.6.3 Vertiefung
An weiterführender Literatur sei z.B. Cummiskey et al. (2020), Lübke et al. (2020), Pearl et al. (2016) und Dablander (2020) empfohlen. Ein gutes Lehrbuch, das auf Kausalinferenz eingeht, ist Huntington-Klein (2022). Praktischerweise ist es öffentlich lesbar. Das Web-Buch Causal Inference for the Brave and True sieht auch vielversprechend aus. Es gibt viele Literatur zu dem Thema; relevante Google-Suchterme sind z.B. “DAG”, “causal” oder “causal inference”.
13.7 Aufgaben
13.8 —

Don muss reich sein.↩︎
Super, Don!↩︎
Der horizontale Balken “|” bedeutet “gegeben, dass”. Ein Beispiel lautet \(Pr(A|B)\): “Die Wahrscheinlichkeit von A, gegeben dass B der Fall ist.↩︎
Ehrlicherweise muss man zugeben, dass auch wissenschaftliche Berichte Daten über Zusammenhänge gerne kausal interpretieren, oft vorschnell.↩︎
engl. randomized, controlled trial, RCT↩︎
Nein, durch das Kontrollieren von
mwird der Kausalpfad vonxzuygeschlossen. Es kann keine kausale Assoziation vonxaufymehr “fließen”.↩︎beeinflussen ist grundsätzlich kausal zu verstehen↩︎
Denken Sie daran, dass Sie keine Nachkommen der UV kontrollieren dürfen, da das den Kausalpfad von der UV zur AV blockieren könnte.↩︎